SQL學習筆記(2)-分組與聚合結果篩選、子查詢
前言
本系列大多部分來自Hahow的課程-SQL的50道練習,學習過程中得到的筆記,文章內容也有部份都是從教材擷取出來,如果有興趣可以去上課看看。
那這章的基本語法其實網路上的網站fooish都講得蠻完善的了,部分文章內容也會引用網站文章內容。
但這次的文章比較多是自己做的圖片,或是個人見解,我希望把程式用白話的方式一一來理解,讓自己能真正的理解他。
開發環境
電腦系統:macOS(Big Sur)
資料庫管理工具:DBeaver
使用語言:SQLite
GROUP BY
GROUP BY是一個很重要的敘述句,常常搭配聚合函數(aggregate_function)使用,
下面的aggregate_function(column_name) ,代表使用的聚合函數以及要進行計算的column的名字
WHERE條件篩選則是看場合使用,
GROUP BY 後面如果放了多個column,代表將這些結果越分越細,同時他也具有ORDER BY的功能。
SELECT column_name(s), aggregate_function(column_name)
FROM table_name
WHERE column_name operator value
GROUP BY column_name1, column_name.2;
詳細解說如下

因為GROUP BY每一個群組會傳回一個資料列,所以自然而然就按照了預設的順序排出了第一筆資料。
但其實這時候分組已經完成了,再看下一張圖:
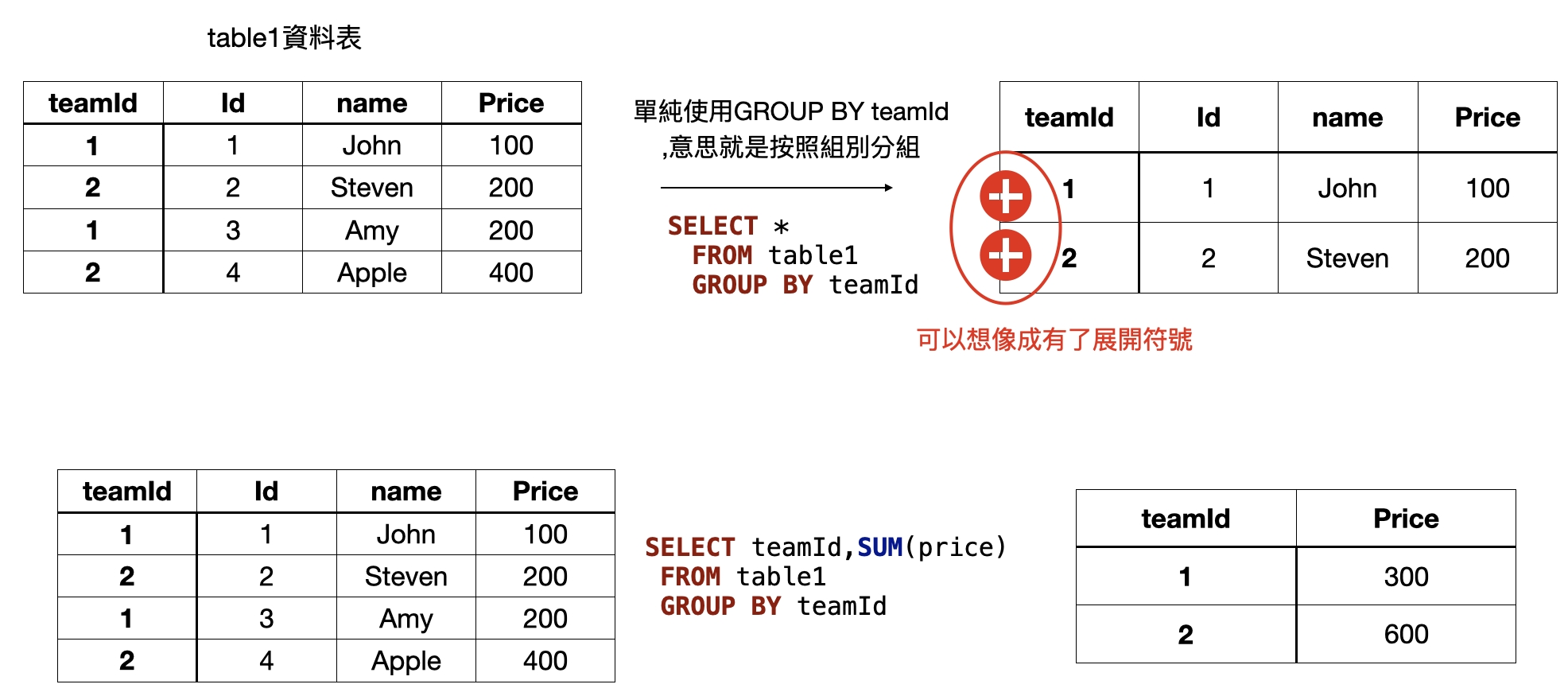
GROUP BY可以想像成把指定的column合併分組之後,但實際上是有展開功能的,裡面的數據並不會消失,
所以如果我們要計算每個組別的價錢總和,就使用GROUP BY 組別名稱 在使用聚合函數SUM(columm),把價錢加總起來,如果在GROUP BY 之後加上的是GROUP BY column_name1, column_name.2,就可以假設在 column_name1之後還有column_name.2分組結果可以展開。
聚合函數COUNT()
SELECT COUNT(column_name) FROM table_name;
COUNT(column_name) 函數用來計算符合查詢條件的欄位紀錄總共有幾筆。
這裡其實需要去理解一下,其實COUNT(column_name)返回的是在指定的column中,欄位值不為NULL的數量,
所以換句話說,如果有NULL值的話並不會被算進去,所以一般不會把有NULL的值放進去做計算,但反觀,
如果都不為NULL的話,就被大家拿來當作查看欄位值有幾筆的函數了,畢竟每個都有值的話,白話說就是數有幾筆數量,但如果在資料表觀測值都不為NULL的情況下,大家的筆數都會一樣,所以這時候就會變成我們常用的
COUNT()或是COUNT(*),意思都一樣。
當COUNT遇上GROUP BY
這是個超常會碰到的用法,在資料皆不為null的情況下,
COUNT的意思是「有幾筆資料」 ,
GROUP的意思則是「分組」
合起來用變成,「分組的組別有幾筆資料」。
範例
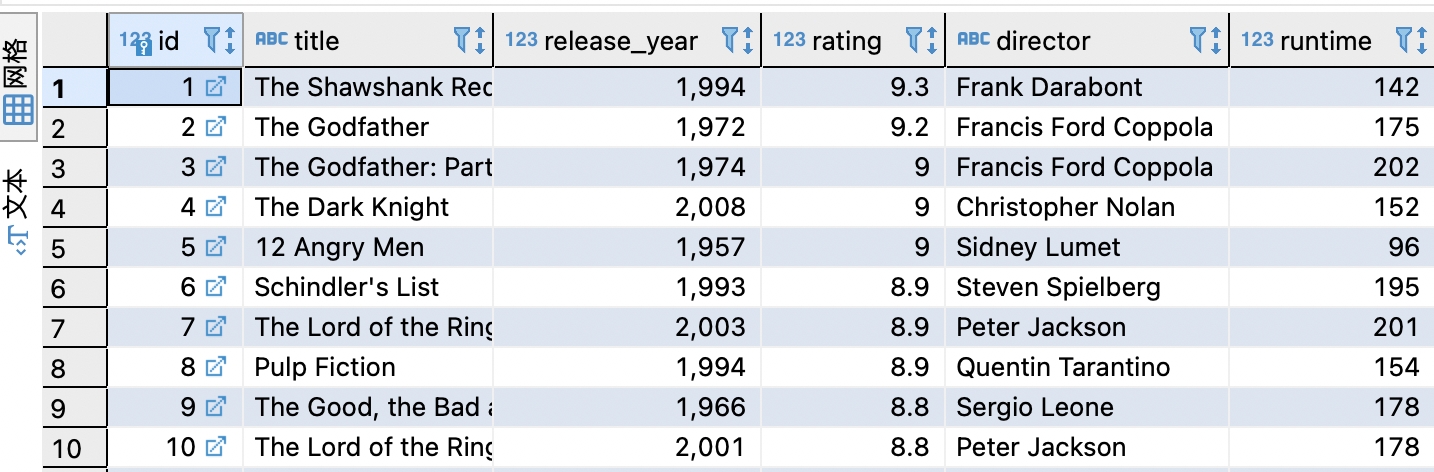
在50道練習當中,某一道題目如下
從 imdb 資料庫的 movies 資料表計算每一年有幾部在 IMDb.com
獲得高評等的經典電影,參考下列的預期查詢結果。
從上面我們可以知道要如何解題
- 首先寫上
SELECTFROM movies,先選好要顯示資料在哪一個資料表 - 接著要計算「每一年」,所以我們把年進行分組
GROUP BY release_year - 再來使用
COUNT(*)計算每一組的比數,意思就是在GROUP BY release_year以年分組後展開後有幾筆數量,也因為大家都不為NULL,所以這個數字也變成了有幾部電影的數量 - 選擇其他要顯示
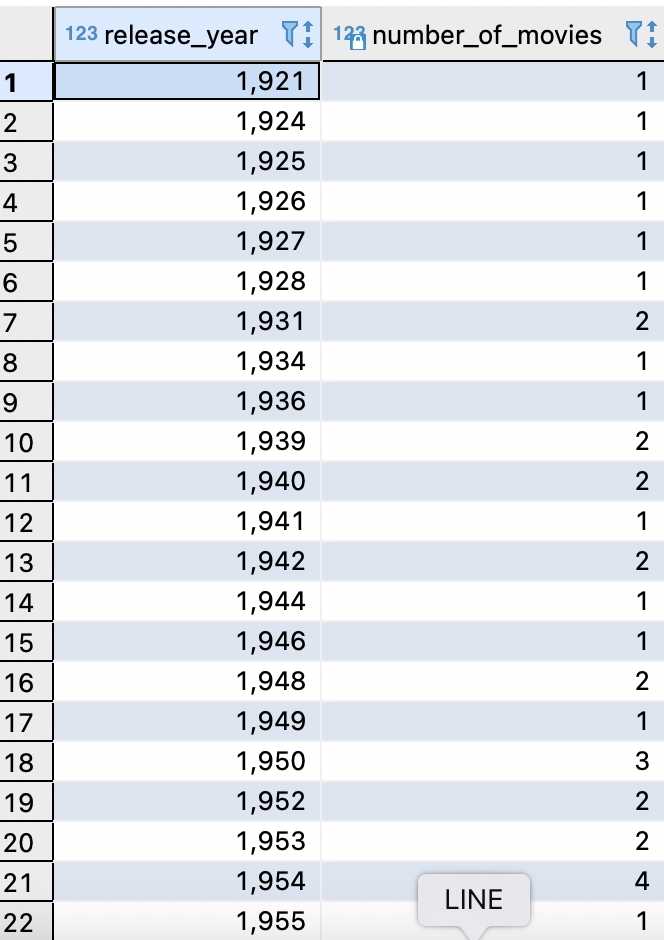
SELECT release_year,COUNT(*) AS number_of_movies
合起來變成:
SELECT release_year,COUNT(*) AS number_of_movies
FROM movies
GROUP BY release_year
結果如下:
HAVING
HAVING跟WHERE一樣都是做條件篩選,但HAVING 後面可以放聚合函數,但WHERE不行,也因為這樣的特性
我們可以把它想成
HAVING是「先計算後篩選」,WHERE則是「先篩選後計算」
SELECT column_name(s), aggregate_function(column_name)
FROM table_name WHERE column_name operator value
GROUP BY column_name1, column_name2...
HAVING aggregate_function(column_name) operator value;
範例:
| O_Id | Price | Customer |
|---|---|---|
| 1 | 1000 | 張一 |
| 2 | 2000 | 王二 |
| 3 | 500 | 李三 |
| 4 | 1300 | 張一 |
| 5 | 1800 | 王二 |
SELECT Customer, SUM(Price)
FROM orders
GROUP BY Customer
HAVING SUM(Price)<1000;
在這邊,我們可以看到由GROUP BY Costomer以客人所進行的分組,以及SUM(Price)的加總,
變成了計算每一個客人總共花了多少錢,但再加上HAVING SUM(Price)<1000,篩選總金額小於1000的值,所以段程式碼的意思是「顯示price總和小於1000的顧客(Customer)」
結果:
| Customer | SUM(Price) |
|---|---|
| 李三 | 500 |
但如果
SELECT Customer, SUM(Price)
FROM orders
GROUP BY Customer
WHERE Price<1000
在WHERE price先進行條件篩選後,這時候連SUM(Price)也不會列入計算,
變成了「計算顧客單筆花費不超過1000的總和」,
結果
| O_Id | Price | Customer |
|---|---|---|
| 1 | 2300 | 張一 |
| 2 | 3800 | 王二 |
| 3 | 0 | 李三 |
Leetcode題目182.(1/13更新)
在DB中Leetcode的182. Duplicate Emails題目如下:
+-------------+---------+
| Column Name | Type |
+-------------+---------+
| id | int |
| email | varchar |
+-------------+---------+
id is the primary key column for this table.
Each row of this table contains an email. The emails will not contain uppercase letters
Write an SQL query to report all the duplicate emails.
Return the result table in any order.
The query result format is in the following example.
Example1.
Input:
Person table:
+----+---------+
| id | email |
+----+---------+
| 1 | a@b.com |
| 2 | c@d.com |
| 3 | a@b.com |
+----+---------+
Output:
+---------+
| Email |
+---------+
| a@b.com |
+---------+
Explanation: a@b.com is repeated two times.
意思就是要找出重複的email,
所以我們可以利用GROUP BY選出重複數量,再利用HAVING先執行在篩選的概念,再把大於2的email count列印出來,解答:
SELECT email AS Email
FROM Person
GROUP BY email
HAVING COUNT(email)>1
子查詢
子查詢就是在一個Select指令內再放入一個Select查詢指令進行查詢,通常是位在Select的Where子句,可以透過子查詢取得查詢條件。
簡單來說,如果我們想在WHERE後面的條件來自於資料表的值、查詢結果,所以通常這個子查詢SELECT後面的欄位只會一個(例如123),因為我們不會在WHERE後面放 where a=(123,456 )這樣在語法上就錯誤了,
使用子查詢撰寫流程技巧

假設我們今天要查詢最短的電影他的資料,
我們要分兩次查詢來完成
- 先查詢「最短」的片長是幾分鐘。
- 再依據前一個查詢結果作為篩選條件。
SELECT MIN(runtime) AS minimum_runtime -- 先查詢「最短」的片長是幾分鐘。
FROM movies;
這時候,假設輸出是
| minimum_runtime |
|---|
| 45 |
所以第二次我們會使用
SELECT *
FROM movies
WHERE runtime = 45; -- 再依據前一個查詢結果作為篩選條件。
得出結果:
| id | title | release_year | rating | director | runtime |
|---|---|---|---|---|---|
| 195 | Sherlock Jr. | 1924 | 8.2 | Buster Keaton | 45 |
接著再把45的地方取代成「取出45的sql語句」,記得加括號
SELECT *
FROM movies
WHERE runtime = (SELECT MIN(runtime) AS minimum_runtime
FROM movies;)
Leetcode題目183.(1/13更新)
在183. Customers Who Never Order中,
題目:
Write an SQL query to report all customers who never order anything.
Return the result table in any order.
The query result format is in the following example.
Input:
Customers table:
+----+-------+
| id | name |
+----+-------+
| 1 | Joe |
| 2 | Henry |
| 3 | Sam |
| 4 | Max |
+----+-------+
Orders table:
+----+------------+
| id | customerId |
+----+------------+
| 1 | 3 |
| 2 | 1 |
+----+------------+
Output:
+-----------+
| Customers |
+-----------+
| Henry |
| Max |
+-----------+
意思就是要從顧客名單Customers table裡面,從Orders挑出還沒點餐的顧客
這題如果我們在已知customerId的情況會這樣寫:
SELECT a.name AS Customers
FROM Customers AS a
WHERE a.id not in (1,3)
所以我們只要利用子查詢返回1.3就可以了!
SELECT a.name AS Customers
FROM Customers AS a
WHERE a.id not in (SELECT customerId
FROM Orders)